OCR Accuracy: What It Is, How to Measure It, and How to Improve
As more processes rely on digitizing printed text via optical character recognition (OCR), ensuring high accuracy in the converted text is crucial for usability and efficiency.
This article explores the core concepts around OCR accuracy – including quantitative metrics like character error rate and word error rate as well as a discussion of the factors that commonly impact accuracy.
We’ll also provide tips for improving scanning and recognition accuracy and give an overview of some of the latest advanced techniques pushing the boundaries of precision text conversion via AI and machine learning models.
Getting clarity on best practices for achieving maximum accuracy will ensure quality OCR text output.
While you are here
Extract every transaction from any bank PDF
Upload a statement from any bank and DocuClipper returns a clean table with dates, amounts, descriptions, and running balance intact. No reformatting before you can reconcile or import.
What is OCR Accuracy?

OCR accuracy refers to the ability of optical character recognition software to produce machine-readable text content from scanned images or PDF files that exactly match the letters, numbers, symbols, and words in the original document.
In other words, the highest quality OCR conversion has no recognition errors when compared side-by-side to the source text. The generated text from OCR should be an identical match.
However, some character or word substitutions or spacing inconsistencies are common even in optimized OCR workflows. So OCR accuracy is formally defined and measured by the rates of these errors across a test data set or digital corpus. Common metrics include:
- Character error rate (CER) – the percentage of total characters incorrectly converted.
- Word error rate (WER) – the percentage of words containing one or more inaccurate characters.
By quantifying metrics like CER and WER on standard test sets, OCR engines can be objectively evaluated and compared for accuracy performance. And improvements to the underlying recognition technology can be validated by reduced error rates.
The next key accuracy metrics are correctness – measuring if a word was properly recognized; completeness – are all words detected; and fragment detection – identifying broken words caused by poor segmentation.
How Does OCR Work?
OCR software converts scanned images of text documents into machine-readable and editable text through a multi-step process:
- Image Acquisition: First, a scanner or camera captures a digital image of the document. Preprocessing techniques are applied to adjust the image, including:
- Deskewing: Correcting tilt or rotation
- Noise removal: Enhancing clarity
- Contrast adjustment: Sharpening text
- Text Recognition: Next, the OCR engine analyzes the glyphs (letter shapes) in the image to identify each character using either pattern matching against known letterforms or feature extraction to identify lines, loops, and other shapes.
- Post-Processing: Finally, the raw OCR text output is formatted into the end text file. Additional checks may catch spelling errors and make corrections by comparing words against a dictionary.
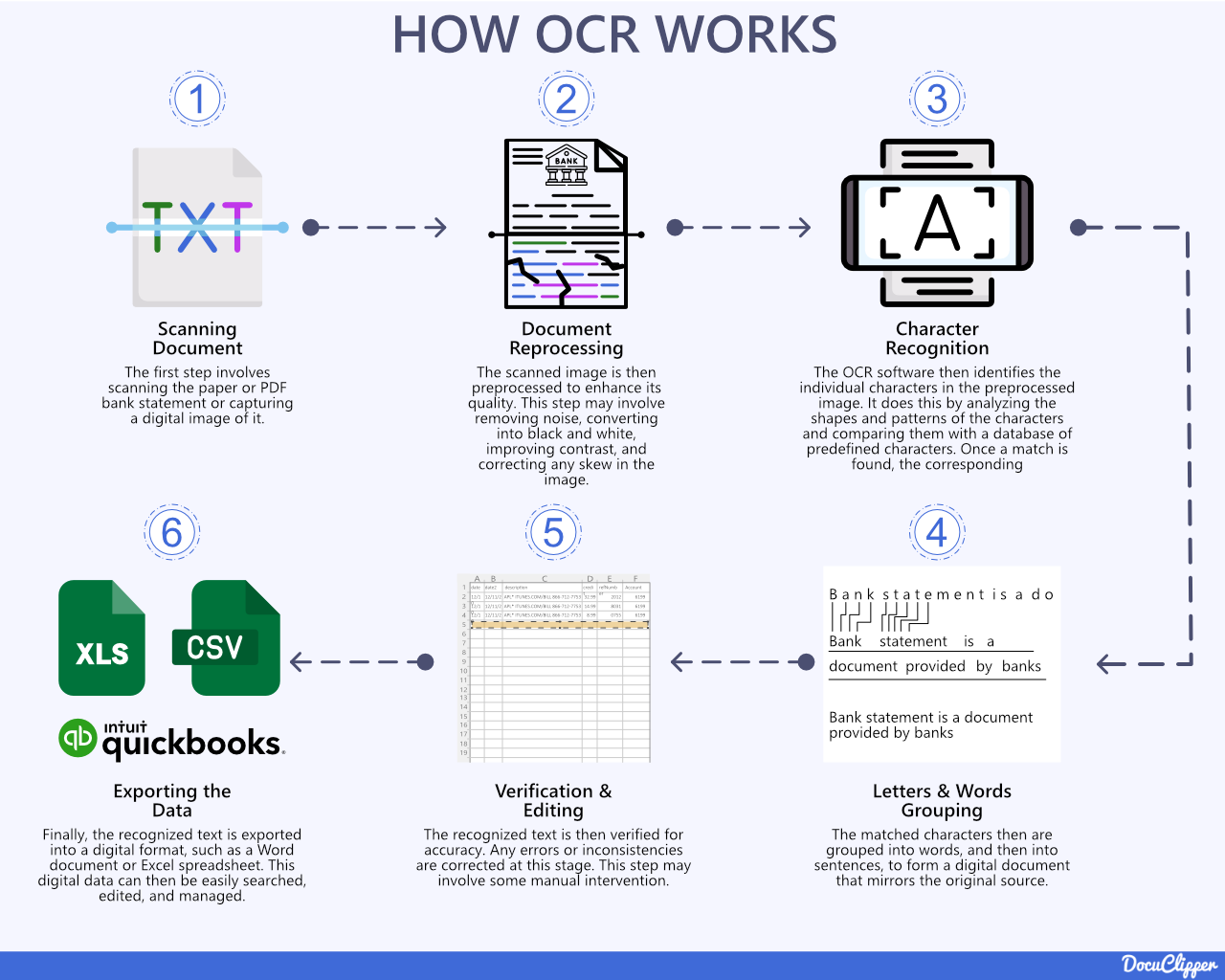
The accuracy of the recognition engine is critical for minimizing any distortions or substitutions introduced in the extraction process.
Advanced OCR software utilizes AI and machine learning to train the recognition engine to analyze fonts, styles, and textual contexts to improve accuracy. (Learn more about OCR vs AI)
Overall, OCR aims to reproduce a perfect textual representation of the scanned document, with maximized accuracy in identifying and retaining all of the original letters, words, formatting, and document structure.
Why is OCR Accuracy Important?
The accuracy rate of an OCR conversion process has major implications for both the usability and efficiency of digitized documents and downstream processes that rely on the extracted text.
Some key reasons why improving OCR accuracy should be a priority include:
- Avoiding Errors in Digital Systems: Poor OCR accuracy introduces inaccuracies like misspelled names or incorrect data values into digital systems and databases if not carefully checked. Even small recognition errors accumulate exponentially.
- Reducing the Need for Manual Review: Higher accuracy means less human effort is required in proofreading and correcting OCR text files manually. Lower accuracy means more staff overhead and costs. Typically, automated OCR data entry boasts an accuracy rate of 99.959% to 99.99%. In contrast, the accuracy rate for human data entry ranges from 96% to 99%. (Data Entry Statistics)
- Enabling Search and Discovery: Retrieving relevant documents hinges on accurate conversion to plaintext. Names, keywords, and other search criteria need to match exactly, or related documents may be missed.
- Supporting Analysis Processes: Accuracy is also crucial when using OCR text for quantification, statistical modeling, machine learning, and training algorithms. Small data errors create major downstream impacts on analysis.
- Compliance and Data Integrity: Many regulatory compliance standards require companies to retain and reproduce accurate and unmodified versions of records over long periods of time. OCR accuracy is key for trustworthy archiving.
Making OCR accuracy central to digitization initiatives saves on resources while also enabling reliable analytics, search, and compliance. Even minor improvements in accuracy have outsized impacts. 56% report that increasing automation of manual tasks helps increase profits. (Accounting Statistics)
How to Calculate OCR Accuracy?
Accurately measuring OCR accuracy is key to benchmarking performance and quantifying improvements in recognition technology.
By comparing raw OCR text output against the original ground truth document text, metrics like character error rate (CER) and word error rate (WER) can be calculated.
This provides objective rates for substitutions, insertions, and deletions of both characters and whole words introduced in the conversion process. Using a standardized test methodology, OCR engines can have their true accuracy quantified – enabling both evaluation and targeted enhancements to the underlying recognition algorithms.
Step 1: Preparing the Data for Analysis
To calculate OCR accuracy metrics like character and word error rates, you first need to gather the raw OCR text output and the “ground truth” or correct text that the OCR output can be compared against.
To prepare this data:
- Assemble a representative sample set of documents for OCR conversion. These should match the target types of documents you want the OCR to handle.
- Manually transcribe the text in these documents 100% correctly – including all spelling, punctuation, and formatting quirks. This flawless text will be used as the ground truth.
- Run the selected documents through the OCR software to generate the machine-extracted text output.
- Keep both the manually prepared true text and the raw OCR text files paired and synced on a per-document basis for a head-to-head comparison.

Now character and word differences can be systematically counted between the ground truth and OCR text on each sample. Tallying these differences across the full sample set allows key rates like CER and WER to be calculated, as explained in the next sections.
Step 2: Run OCR Software
Once you have assembled a representative document test set and manually prepared the correct ground truth text for those samples, the next step is to run the documents through the target OCR system to generate the machine-extracted text.
To perform the OCR conversion:
- Select or acquire the OCR software engine you want to evaluate. This may be a commercial system, open-source tool, or custom in-house recognition engine.
- Import the document image scans into the OCR system per its standard workflow procedures for ingesting and converting files.
- Allow the OCR process to fully complete text recognition and output machine-readable text for each test file.
- Export the raw text results and confirm the OCR system properly processed each document without any errors or workflow issues.
- Pair up and sync the OCR-generated text files with their corresponding ground truth files in your analysis environment for comparison.

At this stage, you now have both the “correct” text and the OCR-extracted text for each sample file which can be used to quantify accuracy rates in the next steps.
Let me know if you need any clarification or have additional details to add for this portion on actually running test files through the OCR system.
Step 3: Calculating Character Error Rate (CER)
Character error rate (CER) is one of the fundamental accuracy measurement metrics for OCR output.
CER measures the ratio of total character-level mistakes in the OCR text compared to the total characters in the ground truth text across a full document set.

The formula for character error rate is:
CER = Number of character errors / Total number of characters in ground truth
Or
CER = (Total characters in ground truth – Number of character errors) / Total characters in ground truth

To calculate CER:
- Take the OCR file and ground truth file for each test document.
- Compare the two files side-by-side.
- Count the individual character substitutions, deletions, and insertions.
- Sum the total character errors across all test documents.
- Sum the total characters in the combined ground truth files.
- Divide the total errors by the total characters to obtain CER.
The lower the CER, the better – with 0% being perfect OCR conversion accuracy. Typical CER rates range from 2-10% for English language OCR on clean scans.
Step 4: Calculating Word Error Rate (WER)
In addition to character error rate, word error rate (WER) is another important OCR accuracy metric.
WER measures the percentage of whole words that contain one or more inaccurate characters when compared to the ground truth text.

The formula for word error rate is:
WER = Number of word errors / Total number of words in ground truth
Or
WER = (Total words in ground truth – Number of word errors) / Total words in ground truth

To find WER:
- Compare the OCR file to the ground truth file for each test document.
- Tally words with incorrect characters as “word errors”.
- Sum total word errors across all test documents.
- Sum total words in the combined ground truth files.
- Divide total word errors by total words to get WER.
Like CER, lower WER percentages indicate higher accuracy. Target WER rates are typically less than 5%.
Tracking both character and word error metrics provides a comprehensive insight into OCR accuracy performance.
Step 5: Analyzing the Results
Once you have calculated the character error rate (CER) and word error rate (WER) for an OCR engine against a representative test set, the final step is interpreting these percentages to evaluate accuracy.
Lower CER and WER values indicate higher accuracy, with 0% being the perfect reproduction of the source text.
However, OCR algorithms, even highly optimized ones, rarely achieve 100% accuracy on complex documents.
For example, DocuClipper trained bank statement converter is trained on over 1,000,000 different bank statements and averaging a 99.5% accuracy rate for all our customers.
But for clean printed scans, normally the target accuracy thresholds are:
- CER: Below 5% for precise data recognition use cases; 2-3% for high performance
- WER: Below 2% for high accuracy needs; <1% for maximum precision
Higher thresholds may be acceptable for some search/indexing uses where minor errors are less impactful.
Analyzing overall rates as well as accuracy by document type can reveal where the OCR technology performs well and areas needing improvement. Documents with lots of tables, specialized terminology, or unusual fonts typically reduce accuracy.
Using these metrics and insights, engineers can continue refining the recognition algorithms to address areas prone to high error rates. This quantifiable approach maximizes the precision of text conversion.
What Affects OCR Accuracy?
OCR conversion accuracy can vary widely depending on the properties of the source document, scan quality, recognition engine capabilities, and other factors.
Below is a breakdown of key elements that influence accuracy levels:
| Item that Affects Accuracy | Description |
| Document Condition | Issues like stains, tears, fading, and artifacts reduce accuracy. Clean, crisp hard copies are ideal. |
| Image Resolution | Higher resolution scans improve precision. Aim for 300+ dpi. Lower res causes errors. |
| Image Quality | Skew, rotation, uneven lighting, and noise degrade OCR reliability. |
| Text Legibility | Small fonts, artistic fonts, handwriting, and poor contrast hurt. Simple fonts are best. |
| Document Layout | Complex tables, columns, and mixed image/text documents challenge accuracy. |
| OCR Software Skill | Algorithms, language models, training data diversity, and handwriting interpretation affect performance. |
| Document Language | Character set size, dialects, semantics, and character proximity change difficulty. Context is key. |
| Color and Background Contrast | High contrast between text and background improves accuracy. Low contrast or patterned backgrounds can cause errors. |
| Type of Scanning Equipment | Advanced scanners with better image processing capabilities can provide cleaner, more accurate inputs for OCR systems. |
| Preprocessing Techniques | The use of image preprocessing techniques like binarization, noise reduction, and contrast adjustment can significantly impact OCR accuracy. |
| Environmental Factors During Scanning | External factors like lighting conditions and scanner stability can impact the quality of the scanned image, thus influencing OCR accuracy. |
| File Format of the Document | Different file formats (PDF, JPEG, PNG, etc.) can affect the OCR process and its accuracy, with some formats being more suitable than others. |
Tracking where and why OCR errors occur allows targeted improvements to process, data and algorithms.
How to Improve OCR Accuracy Best Practices
While many elements can negatively impact OCR precision, there are also a variety of ways to maximize accuracy through optimized scanning, preprocessing techniques, software selection, and configuration.
By following best practices like using high-resolution imagery, binarization and deskewing of documents, boosting contrast, removing artifacts and properly training recognition algorithms, substantial gains in conversion accuracy can be achieved even using mainstream OCR tools.
Use High-Quality Images or Scanners
Start with a high-fidelity document scan. Use an advanced scanner or camera with high resolution/sharpness and consistent lighting. Check for unintended shadows, glare, or distortions that obscure text.
Optimize Image Resolution
Higher resolution enables maximum accuracy. Scan or photograph documents at 300 dpi minimum. 600+ dpi captures finer print and intricate fonts better.
Binarize Images
Converting images to clean black (text) and white (background) simplifies recognition. Binarization tools tailor the thresholding level for each document through OCR preprocessing.
Remove Noise
Eliminate specks, digital artifacts, or stray marks that could be recognized as text using noise reduction and smoothing operations. This clarifies the separation between foreground text and background.
Increase Image Contrast
Boost contrast to sharpen text against the background using brightness and contrast adjustments. Crisper edges and glyphs improve recognizability.
Choose the Right Software
Select OCR software with accuracy-optimized recognition algorithms. Precision gets a boost from machine learning and neural nets trained in identifying diverse fonts, languages, and document types.
Skew Correction
Fix any crooked or angled scans through deskewing modules built into most OCR systems. This alignment step removes distortions impacting character layout analysis.
Put it into practice
Manual copy-paste is where errors begin
Split rows, drifting balances, missed transactions: they all trace back to re-keying. DocuClipper preserves the bank's layout so debits, credits, and totals tie out the first time.
Examples of OCR Accuracy Across Applications
A range of optical character recognition solutions exist for extracting text and OCR data capture from documents. Depending on the focus area, OCR accuracy rates can vary greatly between generic multi-format engines and specialized software tuned for specific document types.
DocuClipper

DocuClipper is a platform that uses Optical Character Recognition (OCR) bank statement technology to extract data from various financial documents like bank statements, credit card statements, invoices, receipts, and brokerage statements. It automates data entry and streamlines tasks like financial analysis, bookkeeping, and expense tracking.
DocuClipper software is trained on over 1,000,000 bank statements and achieves an accuracy of 99.5% accuracy in bank statement processing. This high accuracy is achieved through our state-of-the-art OCR technology and various mechanisms:
And with advanced OCR data visualization, users can also analyze the extracted financial data for insights.
Nanonets
Nanonets is an AI-powered online Optical Character Recognition (OCR) software that efficiently extracts text from various documents such as invoices, bank statements, driver licenses, passports, and more.
Due to their wide range of supported documents, the OCR accuracy is lower than compared to the specialized OCR software such as DocuClipper.
Despite that, Nanonets still achieve a great OCR accuracy level of around 95%-96%.
ABBYY FineReader
ABBYY FineReader is another generic optical character recognition (OCR) software that converts scanned documents, images, and PDFs into editable and searchable formats. It is known for its high accuracy, advanced features, and ability to handle a wide variety of documents.
But unlike the other OCR tools mentioned above, ABBYY FineReader is a desktop and mobile application that works on Windows, Mac, and iOS.
Despite being a generic OCR that supports a wide range of documents, the can achieve an accuracy rate of up to 99.8% for machine-printed text and 97% for handwritten text and can recognize text in over 190 languages, including common languages like English, Spanish, French, and German, as well as less common languages like Arabic, Japanese, and Korean.
Valid8 Financial
Valid8 Financial is a verified financial intelligence and forensic accounting software designed to automate the process of extracting data from financial documents and verifying its accuracy such as bank statements, invoices, and receipts, and provide deep financial analysis.
Valid8 is a specialized OCR solution focused on specific financial documents to aid the financial investigation whether for accountants, lenders, lawyers, or others.
Valid8 has a highly accurate OCR system that can achieve up to 99% accuracy and they verify 100% of the extracted data, ensuring its accuracy and reliability.
OCR Limitations
While optical character recognition technology has improved significantly, there are still some OCR limitations impacting its accuracy and applicability.
Legacy OCR systems struggle with language support, image quality, complex documents, handwriting, and contextual understanding.

(Source)
Accuracy Limitations
OCR accuracy relies heavily on scanning input documents without artifacts, stains, or blurring that can distort the text.
Some character sets, handwriting, smaller font sizes, and special symbols also hamper recognition due to the assumption of clean printed inputs.
Similarly, unique languages, dialects, and niche font families fall outside OCR language model coverage at times.
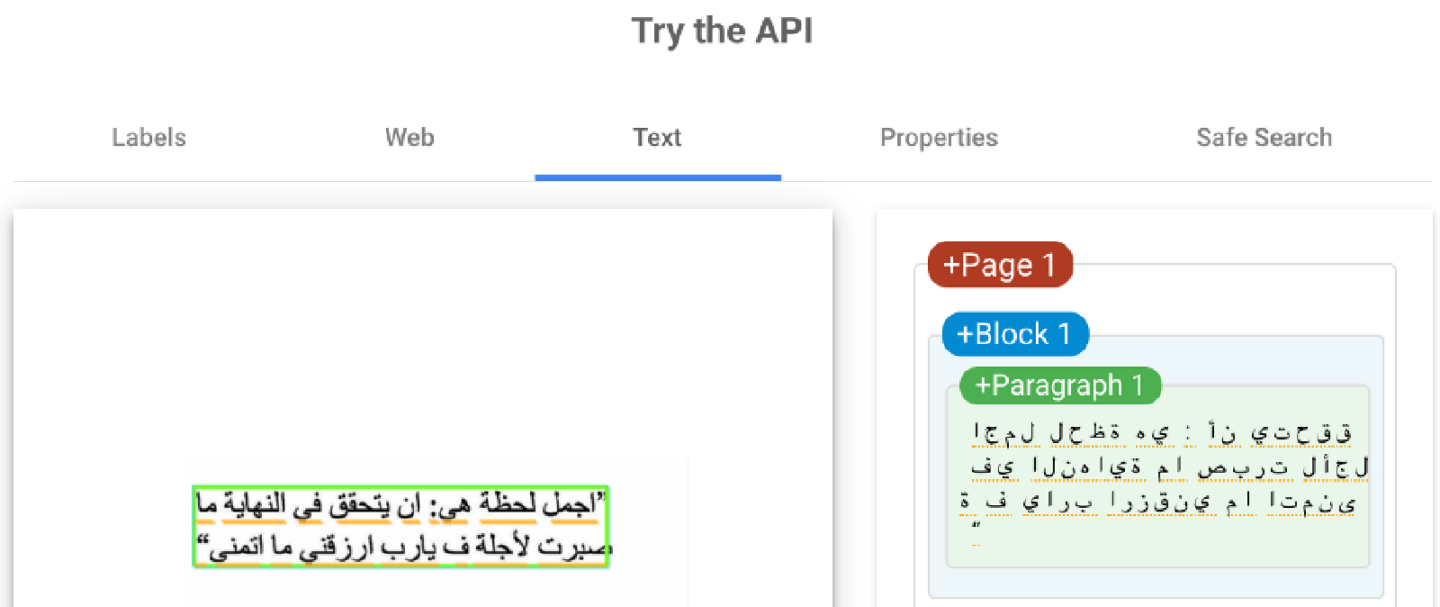
(Image from Google Cloud Vision)
Handwriting and Cursive Text Limitations
Many OCR engines still cannot interpret flowing cursive, stylized, or handprinted writing effectively – especially entire handwritten documents.
The variability of each person’s writing style remains challenging without very large datasets of samples which most recognition systems lack currently.
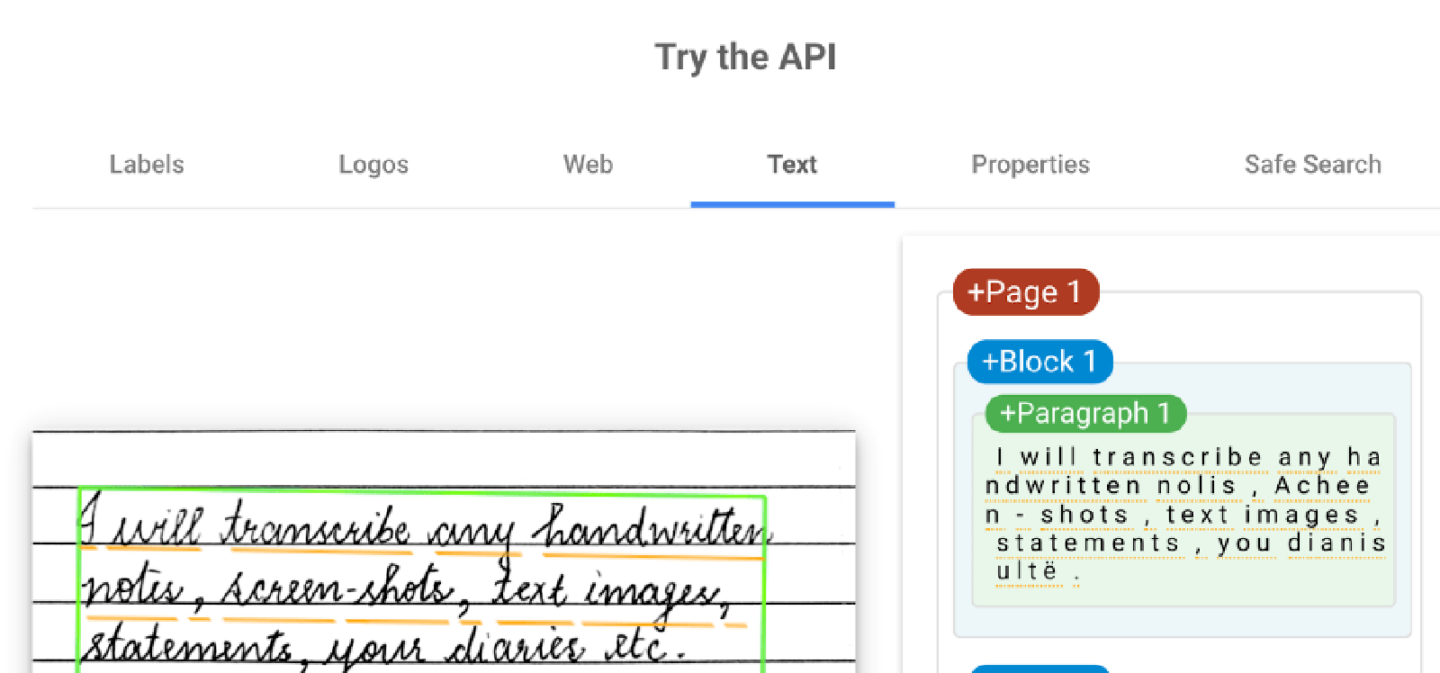
(Image from Google Cloud Vision)
Complex Document Constraints
Intricate digitized documents like insurance claims, engineering schematics, and financial statements with dense tables, multi-font text blocks, and embedded diagrams can strain OCR extraction capabilities leading to significant loss of original structure and formatting details when converted.

Lack of Contextual Document Understanding
While modern AI-enhanced OCR can accurately identify characters and words, most engines lack abilities to fully comprehend the contextual meaning, intent, and relationships between extracted text elements.
Links between concepts, numeric inferences, and document purpose require human-level understanding.
Restricted Use Cases
Despite major progress, OCR retains fundamental constraints around recognizing only specific document types like invoices or standardized forms – but can struggle with niche formats.
Extensive customization is needed for industry-specialized OCRs that can understand domain terminology and data interdependencies.
In summary, today’s OCR systems may falter with non-standard document properties, unconstrained handwriting, complex file structures, contextual inference requirements, or highly-customized use cases – showing key vectors for improvement via emerging techniques.
Conclusion
While optical character recognition software has evolved substantially in capabilities, accuracy rates, and language support, some inherent limitations around image quality assumptions, handwriting recognition, complex document layouts, and contextual understanding still remain.
However, advanced techniques like intelligent document processing solutions that integrate OCR, natural language processing, and machine learning are beginning to overcome these restrictions.
As research continues, the boundaries of automated text extraction and comprehension will steadily expand – increasing adoption across industries.
Though precision gains will gradually taper, robust OCR will eventually fulfill its promise of fully replicating human-level reading and comprehension.
Frequently Asked Questions about OCR Accuracy
Here are some FAQs related to OCR accuracy and the answers:
What is a good accuracy for OCR?
A good OCR accuracy rate typically exceeds 95%. For critical applications like legal or financial document processing, striving for 98% or higher is recommended.
How do you evaluate OCR results?
OCR results are evaluated using metrics like Character Error Rate (CER) and Word Error Rate (WER), comparing OCR output against the original, error-free text.
What are the types of OCR errors?
Common OCR errors include substitution (wrong character recognition), deletion (missing characters), and insertion (adding extra characters).
What can OCR detect?
OCR can detect and convert printed or handwritten text from images or scanned documents into machine-readable form, including characters, words, and basic formatting.
What can cause OCR to fail?
OCR can fail due to poor image quality, complex layouts, unusual fonts, low contrast, language limitations, and errors in the OCR algorithm.
What are the problems with OCR technology?
Problems with OCR include handling cursive handwriting, recognizing rare fonts, managing noisy backgrounds, and inaccuracies with multilingual texts.
What is the difference between OCR and AI OCR?
Traditional OCR relies on pattern recognition, while AI OCR uses machine learning algorithms, improving accuracy and adaptability with different text styles and languages.
Related Articles:
References:
Next step
Upload your first statement free
No credit card required. See extracted transactions in seconds, then export to Excel, CSV, or QBO when you're ready to scale.